
ABSTRAK
Subbidang girus dentata di hipokampus dianggap terlibat secara kritis dalam disambiguasi pengalaman dan tempat episodik yang serupa dengan cara yang bergantung pada konteks. Akan tetapi, sebagian besar bukti empiris berasal dari studi lesi dan gen knock-out pada hewan pengerat, di mana girus dentata terganggu secara permanen dan kompensasi fungsi yang terpengaruh melalui area lain dalam sirkuit memori dapat terjadi. Oleh karena itu, peran akut dan kausal girus dentata di sini masih sulit dipahami. Studi saat ini bertujuan untuk menyelidiki peran akut girus dentata dorsal dalam pembelajaran disambiguasi menggunakan DREADD penghambat reversibel. Tikus dilatih pada tugas diskriminasi lokasi dan belajar membedakan antara lokasi yang diberi hadiah dan tidak diberi hadiah dengan pemisahan kecil (kondisi serupa) atau besar (kondisi tidak serupa). Kontingensi hadiah berubah setelah menerapkan aturan pembalikan, yang memungkinkan kita melacak keterlibatan temporal girus dentata selama tugas. Modulasi DREADD bilateral pada girus dentata mengganggu pembelajaran perolehan awal asosiasi tempat-hadiah, tetapi kinerja pulih dengan cepat ke tingkat dasar dalam sesi yang sama. Pemodelan pola perilaku mengungkapkan bahwa sensitivitas hadiah dan perilaku pergantian dikaitkan secara temporal dengan gangguan yang bergantung pada DG selama pembelajaran perolehan. Dengan demikian, penelitian kami memberikan bukti baru bahwa girus dentata dorsal terlibat secara akut selama pembelajaran perolehan awal asosiasi tempat-hadiah.
1 Pendahuluan
Mengingat tempat-tempat yang terkait dengan peristiwa penting dan menjaga memori ini tetap berbeda saat menghadapi konteks spasial yang serupa merupakan fungsi kognitif penting untuk memandu navigasi spasial dan pengambilan keputusan. Hipokampus terlibat secara kritis dalam memori (Eichenbaum et al. 1996 ), navigasi spasial (O’Keefe dan Dostrovsky 1971 ; O’Keefe 1976 ; O’Keefe dan Nadel 1978 ; McNaughton et al. 1996 ), dan memori spasial (Eichenbaum et al. 1990 ; McDonald dan White 1995 ). Secara khusus, hipokampus mengodekan tempat, lintasan, dan lingkungan individual serta peristiwa sensorik, motivasi, dan peristiwa yang lebih abstrak yang terkait secara temporal (misalnya, asosiasi tempat-hadiah) dalam cara yang bergantung pada konteks (Leutgeb et al. 2007 ; Lansink et al. 2009 ; diulas dalam Lisman et al. 2017 ; Latuske et al. 2018 ; van Dijk dan Fenton 2018 ). Pemetaan konteks yang sangat mirip ke representasi saraf yang berbeda oleh hipokampus sangat penting untuk berhasil membedakan antara konteks dan mencerminkan proses yang lebih umum yang disebut pemisahan pola. Kemampuan untuk membedakan pengalaman serupa diduga menurun pada tahap awal penyakit Alzheimer (Ally et al. 2013 ; Wesnes et al. 2014 ; Zhu et al. 2017 ; Leal and Yassa 2018 ; Lee et al. 2020 ; Parizkova et al. 2020 ; Laczó et al. 2021 ), yang menekankan perlunya memahami dasar saraf dari pemisahan pola.
Subbidang girus dentata (DG) di hipokampus diduga terlibat secara kritis dalam pemisahan pola konteks serupa dengan mengortogonalisasi pola aktivitas masukan menjadi representasi saraf yang terpisah dan berbeda (Marr 1971 ; Treves dan Rolls 1994 ; Hunsaker dan Kesner 2013 ; Knierim dan Neunuebel 2016 ). Bukti empiris untuk fungsi disambiguasi yang dikaitkan dengan DG sebagian besar berasal dari studi lesi perilaku pada primata non-manusia (Hampton dan Murray 2004 ; Lavenex et al. 2006 ) dan hewan pengerat (Gilbert et al. 2001 ; Hunsaker dan Kesner 2008 ; Morris et al. 2012 ; Lee dan Solivan 2010 ), serta studi gene knock-out pada hewan pengerat (McHugh et al. 2007 ; Kannangara et al. 2015 ; Yun et al. 2023 ). Dalam studi-studi ini, disfungsi DG dorsal (dDG) biasanya dikaitkan dengan kemampuan terganggu untuk membedakan antara posisi-posisi yang berdekatan (Gilbert et al. 2001 ; Hunsaker dan Kesner 2008 ; McHugh et al. 2007 ; Morris et al. 2012 ; Kannangara et al. 2015 ; Oomen et al. 2015 ; Yun et al. 2023 ) dan lokasi objek (Lee dan Solivan 2010 ), dengan hewan-hewan membuat lebih banyak kesalahan dalam mengidentifikasi lokasi yang dikaitkan dengan imbalan. Meskipun kesimpulan umum dari studi-studi ini adalah bahwa disfungsi dDG merusak kemampuan untuk memisahkan secara spasial lokasi-lokasi stimulus dari satu sama lain, tetap sulit untuk menafsirkan dampak lesi pada diskriminasi perilaku, mengingat bahwa lesi-lesi seringkali kasar dan permanen dan dapat mengakibatkan kompensasi fungsi-fungsi yang terpengaruh melalui area-area lain.
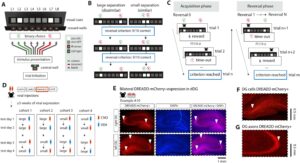
Bahasa Indonesia: Untuk lebih memahami keterlibatan akut dan kausal DG dalam pembelajaran disambiguasi spasial dalam tugas yang dirancang untuk melibatkan diskriminasi perilaku dengan kontrol spasial dan temporal yang lebih banyak, kami secara sementara mengganggu dDG dengan senyawa inhibitory Designer Receptors Exclusively Activated by Designer Drugs (DREADDs; Roth 2016 ) pada tikus yang melakukan tugas diskriminasi lokasi (Gambar 1A ; Oomen et al. 2013 ; Oomen et al. 2015 ). Secara khusus, kami menargetkan populasi sel eksitatori dalam dDG, yang terdiri dari sel granula dan sel lumut, dengan yang pertama memproyeksikan secara padat ke area CA3. Tugas perilaku tersebut menguji pembelajaran spasial pada tikus yang membedakan antara lokasi yang diberi hadiah dan yang tidak diberi hadiah. Untuk melacak keterlibatan temporal dDG dan menghindari bias spasial ke satu sisi kotak, kontingensi hadiah berbalik setelah setiap 9 dari 10 respons yang benar berturut-turut (Gambar 1B,C ; Oomen et al. 2013 ). Kami menemukan gangguan signifikan pada kinerja diskriminasi ketika DG terganggu, tetapi hanya selama fase perolehan tugas; kinerja pulih ke tingkat dasar dalam sesi tes. Untuk memahami aspek pembelajaran mana yang terpengaruh, kami menerapkan model perilaku yang sesuai dengan tugas yang ada dan mampu menyelidiki parameter pembelajaran perilaku (Sutton dan Barto 2018 ; Metha et al. 2020 ). Secara khusus, kami mengukur pembelajaran yang digerakkan oleh hadiah uji-ke-uji dengan model pembelajaran penguatan (RL) dan kecenderungan untuk bertahan dalam perilaku pilihan dengan model ketekunan RL (PRL). Model perilaku ini mengungkapkan bahwa defisit perolehan yang bergantung pada DG secara temporal dikaitkan dengan penurunan kepekaan terhadap hadiah dan peningkatan perilaku pergantian. Dengan demikian, penelitian kami memberikan bukti baru bahwa dDG terlibat secara akut tetapi sementara selama pembelajaran diskriminasi spasial.
2 Metode
2.1 Hewan
Dua puluh tikus Lister-Hooded jantan (Envigo, Belanda), berusia 7–8 minggu saat tiba, ditempatkan berpasangan dalam kandang polikarbonat standar dengan siklus siang hari 12 jam terbalik. Hewan-hewan dibiasakan dengan kandang rumah mereka dengan air dan makanan sepuasnya dan ditangani setiap hari oleh para peneliti selama 1 minggu. Untuk memotivasi hewan agar melakukan tugas perilaku, hewan-hewan dibatasi makanannya hingga maksimal 85% dari kurva pertumbuhan standar yang diperoleh dalam kondisi pemberian makan sepuasnya dan diberi akses air sepuasnya . Semua prosedur eksperimen dilakukan sesuai dengan European Directive 2010/63/EU, pedoman dari Federation of European Laboratory Animal Science Associations, NIH Guide for the Care and Use of Laboratory Animals, dan telah disetujui oleh komite etik nasional dan institusional.
2.2 Tugas Perilaku Dengan Manipulasi DREADD
Untuk menyelidiki pemisahan pola spasial, hewan dilatih dan diuji pada tugas diskriminasi lokasi (LD) (Gambar 1A ). Tugas LD diadaptasi dari tugas platform operan LD layar sentuh untuk menguji memori spasial yang bergantung pada hipokampus pada tikus (McTighe et al. 2009 ; Svensson et al. 2016 ) dan mencit (Clelland et al. 2009 ; Creer et al. 2010 ; Coba et al. 2012 ). Dalam tugas LD kami, sumur imbalan diposisikan di bawah masing-masing dari 8 lokus stimulus yang disajikan pada layar, alih-alih satu sumur imbalan yang terletak di sisi yang berlawanan dengan dinding layar (Gambar 1A ; seperti pada McTighe et al. 2009 ). Desain ini mengurangi waktu pelatihan tikus (CAO, pengamatan yang tidak dipublikasikan), kemungkinan karena lokasi stimulus dan imbalan yang selaras secara spasial memungkinkan pembentukan asosiasi stimulus-hasil yang lebih cepat. Selain itu, tikus melakukan percobaan yang diinisiasi sendiri, dengan menghadap layar menggunakan tusukan hidung bagian tengah untuk memastikan bahwa hewan tersebut terpapar dengan jelas pada stimulus saat percobaan dimulai.
Hewan dilatih dalam kotak operan otomatis (lebar 52 cm × tinggi 40 cm × kedalaman 50 cm) dengan tiga dinding aluminium hitam yang terpasang pada layar monitor hitam (lebar 64 cm × kedalaman 3 cm, Liyama Prolite B2776HDS) dan lantai batang logam dengan jarak 1 cm. Strip polioksimetilen hitam dengan 8 sumur hadiah (masing-masing tinggi 5 cm × lebar 6 cm × kedalaman 4 cm) terletak di bawah layar, sehingga hadiah air sukrosa 15% 0,1 mL dapat diberikan dari pompa jarum suntik melalui tabung plastik. Isyarat visual yang identik disajikan di layar sebagai kotak putih (lebar 2 cm × tinggi 2 cm, jarak stimulus pusat ke pusat = 6 cm) di 8 kemungkinan lokasi stimulus yang sesuai dengan sumur hadiah yang terletak di bawah layar. Stimuli dihasilkan dengan Psychtoolbox-3 di MATLAB (Brainard 1997 ) dan pengaturan tugas dikontrol dengan skrip yang ditulis khusus di MATLAB.
2.2.1 Pelatihan Perilaku Awal
Dalam fase pra-pelatihan LD awal, hewan belajar untuk merespons secara selektif dan andal ke 1 dari 8 kemungkinan lokasi yang diberi isyarat (L1–L8, lihat Gambar 1A ) dan lokasi yang diberi hadiah dipilih secara acak dari 8 lokasi tersebut setiap percobaan. Pada awal percobaan, lampu LED hijau menyala di sumur tengah, setelah itu hewan dapat memulai percobaan dengan menusuk hidung ke sumur hadiah tengah setidaknya selama 0,3 detik. Setelah inisiasi percobaan berhasil, hewan menerima hadiah air sukrosa dengan probabilitas 20% untuk memotivasi hewan untuk memulai percobaan sendiri. Jika hewan menusuk dengan benar di lokasi yang diberi isyarat (“percobaan yang benar”), hadiah air sukrosa segera diberikan di sumur hadiah yang terletak di bawah stimulus isyarat yang sesuai. Namun, jika hewan menusuk dengan tidak benar, yaitu. di lokasi tusuk hidung yang tidak diberi isyarat (“percobaan yang salah”), lampu LED putih yang ditempatkan di dinding di seberang panel tusuk hidung menyala selama 3 detik, diikuti oleh waktu habis selama 5 detik. Isyarat visual menghilang setelah pilihan didaftarkan oleh sensor tusuk hidung yang terletak di setiap sumur hadiah yang sesuai. Setelah periode pilihan, percobaan berakhir, dan interval antar percobaan (ITI) selama 10 detik diikuti, di mana layar monitor tetap hitam untuk memaksimalkan keunggulan stimulus isyarat putih selama percobaan. Untuk melanjutkan ke fase percobaan berikutnya, hewan harus menyelesaikan 90 percobaan dalam satu sesi selama 40 menit dengan kinerja minimal 80% percobaan yang benar selama dua sesi berturut-turut.
2.2.2 Bedah Injeksi Virus
Setelah menyelesaikan prapelatihan, satu kelompok hewan ( N = 20 tikus) disuntik secara bilateral dalam dDG dengan pAAV5-CaMKIIa-hM4D(Gi)-mCherry (titer virus ≥ 3 × 10 12 vg/ml, Addgene, North Carolina, AS). DREADD penghambat diaktifkan oleh ligan buatan clozapine-N-oksida (CNO; Hsiang et al. 2014 ; Roth 2016 ; Matos et al. 2019 ; Visser et al. 2020 ; Domi et al. 2021 ; Lesuis et al. 2021 ; tetapi lihat Gomez et al. 2017 ) dan memanipulasi aktivitas saraf sementara pada neuron target selama sekitar 2 jam setelah injeksi CNO (Roth 2016 ). Prosedur pembedahan dilakukan sesuai dengan prosedur operasi standar untuk injeksi virus intraserebral. Hewan menerima injeksi subkutan buprenorfin (0,01–0,05 mg/kg) dan meloksikam (2 mg/kg) 20–30 menit sebelum anestesi. Hewan dibius dengan isoflurana (tingkat induksi: 3%–5% isoflurana; tingkat pemeliharaan: 0,5%–3% isoflurana) dan disuntik dengan 0,48 μL vektor virus DREADD per lokasi injeksi pada laju aliran 0,056 μL per menit dan waktu tunggu pascainjeksi 10 menit. Injeksi dilakukan dengan injektor nanoliter otomatis (Nanoject II, Drummond Scientific Company, AS) pada koordinat anterior-posterior (AP), medial-lateral (ML) dan dorsal-ventral (VL) berikut relatif terhadap Bregma: -2,7 mm AP, ±1,2 mm ML, -3,7 mm DV di DG dorsal anterior; -3,7 mm AP, ±2,0 mm ML, -3,1 mm DV di DG dorsal posterior. Untuk penyebaran virus di DG, lihat bagian 3. Setelah pembedahan, hewan ditempatkan dalam kandang soliter selama 3–7 hari dengan makanan lunak dan air sepuasnya .
2.2.3 Pelatihan Perilaku
Setelah pulih dari operasi penyuntikan virus, hewan ditempatkan berpasangan lagi dan dilatih ulang pada paradigma prapelatihan hingga mencapai tingkat kinerja yang diamati sebelum operasi. Hewan kemudian maju ke fase pelatihan, di mana mereka belajar membedakan antara lokasi stimulus yang diberi hadiah dan yang tidak diberi hadiah dengan jarak pemisahan sedang (18 cm). Hewan memulai setiap percobaan dengan cara yang sama seperti pada fase prapelatihan, setelah itu hewan disajikan dengan dua isyarat visual dan belajar mengidentifikasi lokasi mana dari kedua lokasi yang diberi hadiah melalui coba-coba. Hewan menerima hadiah air sukrosa (0,1 mL, 15% sukrosa dalam air) segera setelah menusuk jika pilihannya benar dan waktu istirahat 5 detik jika pilihannya salah, yang diisyaratkan oleh penerangan LED pada kotak pelatihan (seperti yang dijelaskan untuk fase prapelatihan). Setelah melakukan 9 dari 10 percobaan yang benar secara berurutan, kontingensi hadiah dibalik untuk menilai pembelajaran pembalikan dan menghindari bias spasial ke satu sisi kotak (Gambar 1B,C ). Hewan dilatih selama 6 sesi, di mana lokasi setiap pasangan stimulus unik divariasikan selama sesi dengan jarak pemisahan yang konsisten (18 cm per pasangan lokasi, pemisahan sedang): lokasi 1 dan 3 (L1–L3), 2 dan 4 (L2–L4), 3 dan 5 (L3–L5), 4 dan 6 (L4–L6), 5 dan 7 (L5–L7), dan 6 dan 8 (L6–L8).
2.2.4 Pengujian Perilaku Dengan dan Tanpa Intervensi DREADD
Bahasa Indonesia: Setelah menyelesaikan pelatihan dengan jarak sedang, hewan siap untuk pengujian pada tugas LD dengan pemisahan kecil (L4–L5, jarak = 6 cm) atau jarak pemisahan besar (L2–L7, jarak = 30 cm) selama neurointervensi. Tiga puluh hingga empat puluh menit sebelum pengujian, hewan menerima suntikan ip dengan ligan DREADD clozapine-N-oxide (CNO; 3 mg/1 mL/kg dalam larutan garam, HelloBio.com ) atau larutan garam (vehicle, VEH; 1 mL/kg) sebagai perlakuan kontrol. Hewan diuji pada setiap kombinasi pemisahan tugas dan neurointervensi dalam total empat sesi (satu sesi per hari pengujian, Gambar 1D ): pemisahan kecil dengan wahana (selanjutnya disingkat Small-VEH) atau CNO (Small-CNO) dan pemisahan besar dengan wahana (Large-VEH) atau CNO (Large-CNO). Untuk mengimbangi dampak manipulasi tugas pada kinerja LD, hewan dibagi menjadi empat kelompok yang masing-masing diuji pada manipulasi tugas yang berbeda pada setiap hari pengujian (Gambar 1D ). Prosedur untuk sesi pengujian LD sama seperti yang dijelaskan untuk sesi pelatihan LD, dengan satu-satunya perbedaan bahwa jumlah pembalikan maksimum ditetapkan menjadi 6 dalam waktu 60 menit, sehingga hewan memiliki paparan pengujian yang sama di seluruh sesi.
2.3 Histologi
Setelah percobaan selesai, hewan menerima dosis mematikan 1 mL 20% euthasol melalui suntikan ip dan diperfusi transkardial dengan 4% paraformaldehyde (PFA) dalam phosphate buffered saline (PBS) untuk memverifikasi ekspresi virus di DG dorsal. Otak diekstraksi dan disimpan dalam larutan PFA 4% pada suhu 4 °C selama 2 hari. Untuk persiapan pengirisan, otak direndam dalam sukrosa 15% dalam PBS selama 1 hari dan sukrosa 30% dalam PBS (pH 7,3) selama 2 hari. Otak diiris menjadi irisan koronal 40 μm menggunakan mikrotom dan disimpan semalam dalam PBS pada suhu 4 °C. Untuk mewarnai sel fluoresen yang ditandai dengan mCherry, irisan diwarnai dengan DAPI (300 nM dalam PBS, Sigma). Potongan-potongan tersebut direndam dalam DAPI selama 5 menit pada suhu ruangan, setelah itu DAPI dikeluarkan dan dicuci 3 kali dengan PB (pH 7,3). Potongan-potongan yang diwarnai dipasang pada slide mikroskop (SuperFrost Plus, Thermo Scientific) dan disimpan semalam pada suhu ruangan. Potongan-potongan tersebut divisualisasikan menggunakan mikroskop fluoresensi (Leica Microsystems DM300) pada perbesaran 10x untuk menangkap ekspresi virus dalam dDG (Gambar 1E–G , Gambar S1 ).
2.4 Analisis Data
2.4.1 Diskriminasi Lokasi dan Kinerja Pembalikan
Kami pertama-tama menentukan bagaimana perilaku tugas dan aktivitas penggerak dimodulasi oleh jarak stimulus dan manipulasi DREADD dari DG selama tugas LD.
Kinerja diskriminasi lokasi diukur dengan ukuran perilaku berikut. Jumlah percobaan yang dibutuhkan hewan untuk mencapai kriteria pembalikan 9 dari 10 pilihan yang benar berturut-turut didefinisikan sebagai percobaan untuk kriteria (TTC; Oomen et al. 2013 ; McTighe et al. 2009 ), di mana nilai TTC yang rendah dan tinggi menunjukkan pembelajaran yang cepat dan lambat dari kontingensi hadiah, masing-masing. Proporsi kesalahan dihitung sebagai jumlah pilihan yang salah dibagi dengan jumlah total pilihan dan menunjukkan seberapa baik hewan membedakan antara lokasi target dan nontarget yang diberi isyarat. Latensi respons (dalam detik) didefinisikan sebagai waktu dari permulaan stimulus hingga hewan menyodok lokasi target atau nontarget (L4 dan L5 untuk sesi Kecil; L2 dan L7 untuk sesi Besar; Gambar 1B ). Jumlah tusukan kosong didefinisikan sebagai jumlah tusukan hidung yang dilakukan pada lubang yang tidak pernah diberi isyarat atau diberi hadiah selama sesi pengujian (L1, L3, L6, dan L8 untuk sesi Kecil dan Besar; Gambar 1B ). Jumlah tusukan kosong (yaitu, pada lubang yang tidak diberi isyarat) ditentukan untuk menyelidiki seberapa tepat hewan menusuk lubang target dan lubang yang tidak diberi isyarat.
Setiap ukuran kinerja tugas dibandingkan antara pemisahan tugas dan kondisi perlakuan untuk setiap fase pembelajaran. Ukuran dihitung secara terpisah untuk setiap fase pembelajaran untuk membedakan kinerja tugas di berbagai fase pembelajaran, yaitu fase akuisisi (Acq, di mana hewan belum menyesuaikan perilakunya dengan pembalikan pertama) dan fase pembalikan berikutnya, di mana urutan peringkat temporal pembalikan ditunjukkan oleh R1 , R2 , … , Rn . Kami memasang model campuran linier umum (GLMM) untuk setiap ukuran perilaku untuk memperhitungkan efek acak silang dari data (Persamaan 1 ; fungsi fit_glm , MATLAB), karena faktor model perlakuan dan pemisahan disilangkan dalam setiap hewan. Setiap GLMM dipasang dengan serangkaian distribusi, termasuk distribusi normal, Gaussian invers, Poisson, dan gamma, dan kecocokan model terbaik ditentukan sebagai model dengan jumlah kesalahan kuadrat (SSE) terendah. Kami kemudian melakukan ANOVA pada koefisien model untuk menguji efek utama dan interaksi dari perlakuan dan pemisahan. Perbandingan post hoc antara kondisi perlakuan untuk setiap pemisahan dilakukan dengan uji Wald pada estimasi mean marginal (fungsi emmeans , MATLAB , kode sumber: github.com/jackatta/estimated-marginal-means ), dihitung sebagai mean dari setiap faktor model yang disesuaikan dengan mean dari faktor model lainnya. Semua nilai p post hoc disesuaikan dengan koreksi false discovery rate untuk beberapa perbandingan. Tingkat signifikansi ditetapkan pada p < 0,05.
GLMM ditetapkan dalam bentuk umum sebagai berikut:

2.4.2 Aktivitas Lokomosi Selama Perilaku Tugas
Bahasa Indonesia: Untuk mengontrol efek DREADD non-spesifik pada penggerak, kami juga mengukur posisi tubuh tikus dari data video yang dikumpulkan pada 25 fps untuk sebagian hewan yang menunjukkan ekspresi DREADD bilateral ( N = 7). Bingkai video diproses dengan DeepLabCut (Mathis et al. 2018 ), program pelacakan semi-otomatis yang menggunakan jaringan saraf dalam untuk memperkirakan posisi bagian tubuh berdasarkan bingkai uji yang diberi label secara manual. Kami memberi label 6 bagian tubuh setiap 80–120 bingkai per hewan, termasuk bagian tengah tubuh, bahu kiri, bahu kanan, pangkal leher, dan moncong. Untuk memperoleh perkiraan posisi tubuh yang andal, kami merata-ratakan koordinat bagian tubuh ke koordinat pusat massa ( X , Y ) untuk setiap bingkai. Artefak noise dikurangi dengan menghapus koordinat estimasi yang berada di luar kotak LD, setelah itu data pelacakan dihaluskan dengan filter rata-rata bergerak (lebar: 10 sampel bingkai) (fungsi smoothdata , MATLAB) dan filter interpolasi diterapkan ke jendela 100 msec (fungsi interp1 , MATLAB). Aktivitas lokomosi diukur sebagai kecepatan tubuh, yang didefinisikan sebagai jarak tempuh per detik (cm/s) dari awal uji coba hingga akhir uji coba. Jarak tempuh dihitung sebagai akar kuadrat dari jumlah selisih kuadrat antara setiap pasangan koordinat X dan selisih kuadrat antara setiap pasangan koordinat Y. Kecepatan tubuh dibandingkan antara empat kombinasi kondisi pemisahan dan perlakuan yang berbeda dengan GLMM, secara terpisah untuk setiap pembalikan. Perbandingan post hoc antara kondisi perlakuan dibuat dengan estimasi rata-rata marginal.
2.4.3 Penyesuaian Data Pilihan dengan Model Pembelajaran Penguatan
Untuk memahami aspek pembelajaran mana selama diskriminasi spasial yang terpengaruh oleh DREADD, kami memperkirakan parameter pembelajaran yang mendasari pembelajaran tempat-hasil yang didorong oleh penghargaan menggunakan model pembelajaran penguatan (selanjutnya disebut sebagai “model RL”; Rescorla dan Wagner 1972 ; O’Reilly dan den Ouden 2015 ; Sutton dan Barto 2018 ; Metha et al. 2020 ). Model RL disesuaikan dengan perilaku pilihan untuk melacak perubahan uji-ke-uji dalam pembelajaran yang didorong oleh penghargaan dari waktu ke waktu. Ini memungkinkan kami untuk menentukan apakah defisit disambiguasi spasial yang bergantung pada DG yang diamati dalam penelitian sebelumnya (Gilbert et al. 2001 ; Hunsaker dan Kesner 2008 ; Morris et al. 2012 ; Lee dan Solivan 2010 ) dapat dijelaskan oleh defisit dalam memperoleh asosiasi tempat-hasil. Dengan demikian, kami menerapkan model perilaku untuk menyelidiki parameter pembelajaran perilaku.
Secara khusus, model RL memungkinkan kami untuk menyelidiki apakah pembelajaran asosiasi tempat-hasil didorong oleh hadiah, yaitu dengan menilai laju pembelajaran ( parameter alfa ) dan kecenderungan hewan untuk memilih lokasi yang diberi hadiah berdasarkan nilai hadiah yang terkait dengan setiap tempat ( parameter beta ). Pada gilirannya, kuantifikasi parameter terkait hadiah ini dapat menjelaskan mengapa kami mengamati defisit selektif yang didorong dDG selama fase perolehan tugas (Gambar 2D,F ), ketika hewan mungkin memperoleh asosiasi tempat-hasil. Selain itu, untuk menentukan apakah hewan bertahan dalam pilihan mereka meskipun menerima hadiah dalam percobaan sebelumnya, kami memperluas model RL dengan parameter ketekunan tambahan ( parameter delta ; selanjutnya disebut sebagai model Perseverance RL, “model PRL”; disesuaikan dari Metha et al. 2020 ).
Bahasa Indonesia: Untuk memodelkan bagaimana perilaku pilihan hewan selama tugas LD dimodulasi oleh jarak stimulus dan manipulasi DREADD dari DG, kami menyesuaikan data pilihan setiap hewan dengan model RL dan PRL. Model-model tersebut kemudian dibandingkan menggunakan Kriteria Informasi Akaike (AIC; Akaike 1998 ) untuk menentukan mana yang paling sesuai dengan perilaku setiap hewan. Kami pertama-tama menyesuaikan model RL dengan data pilihan (Rescorla dan Wagner 1972 ; Metha et al. 2020 ; Sutton dan Barto 2018 ). Model ini disusun sebagai berikut. Untuk setiap percobaan t , probabilitas memilih stimulus yang tepat (
) dihitung dengan fungsi sigmoid (Persamaan 2 ) yang memodelkan bagaimana nilai stimulus yang dipelajari (
Dan
) diterjemahkan menjadi pilihan (Persamaan 3 ). Persamaan sigmoid umumnya mengikuti perilaku yang diamati pada manusia dan hewan pengerat yang melakukan tugas pembalikan (O’Reilly dan den Ouden 2015 ) di mana subjek lebih cenderung memilih opsi dengan nilai stimulus yang lebih tinggi, tetapi juga dapat beralih ke pilihan yang kurang bernilai dari waktu ke waktu melalui pergantian spontan. Dengan demikian, probabilitas pilihan tetap stokastik, yaitu tanpa mencapai nilai 0 atau 1. Nilai setiap stimulus (
Dan
) dimodelkan dengan persamaan Rescorla–Wagner (Rescorla dan Wagner 1972 ) yang mengikuti pembelajaran berbasis kesalahan prediksi, di mana stimulus memperoleh nilai hadiah ketika hasil pada percobaan sebelumnya (
) melebihi nilai hadiah yang diprediksi pada percobaan sebelumnya (
). Yang penting, kesalahan prediksi berskala dengan tingkat pembelajaran alpha , yang menunjukkan seberapa cepat hewan memperoleh nilai hadiah ketika nilai stimulus berubah di seluruh percobaan (misalnya, alpha rendah menunjukkan pembelajaran yang lambat). Kami kemudian memperkirakan sensitivitas terhadap hadiah dengan parameter kemiringan beta , yang menunjukkan seberapa kuat pilihan (biner) hewan mengikuti nilai stimulus (dinilai) di seluruh percobaan (misalnya, beta rendah menunjukkan bahwa hewan memilih lebih dekat ke tingkat peluang, daripada mengikuti nilai stimulus). Untuk model Perseverance RL (PRL), model RL diperluas dengan parameter delta yang memperkirakan tingkat ketekunan hewan dalam memilih percobaan sebelumnya (Persamaan 4 ). Nilai delta positif menunjukkan bahwa hewan lebih mungkin merespons di sisi yang sama dengan percobaan sebelumnya (ketekunan). Sebaliknya, nilai negatif menunjukkan bahwa hewan lebih mungkin beralih dari sisi ke sisi pada percobaan berturut-turut (pergantian). Dalam model ini (Persamaan 4 )
Dan
adalah variabel indikator, yang mengambil nilai 1 jika stimulus yang sesuai dipilih, dan 0 jika tidak. Parameter alpha , beta , dan delta diestimasikan untuk setiap hewan berdasarkan kecocokan kemungkinan maksimum dengan data pilihan. Kami kemudian membandingkan parameter alpha , beta , dan delta antara kondisi perlakuan untuk setiap kondisi pemisahan dengan GLMM sebagaimana ditentukan dalam Bagian 2.4.1 . Semua model dipasang dengan nilai offset konstan 0,5 untuk mencerminkan probabilitas pilihan pada tingkat peluang di awal setiap sesi. Nilai p disesuaikan dengan koreksi FDR untuk beberapa perbandingan. Tingkat signifikansi ditetapkan pada p < 0,05.

3 Hasil
Untuk mempelajari peran girus dentata dorsal (dDG) dalam menghilangkan ambiguitas representasi spasial yang serupa, kami secara selektif memodulasi dDG dengan DREADD penghambat (AAV5-hM4D(Gi)-mCherry) pada tikus Lister Hooded ( N = 20) yang melakukan tugas diskriminasi lokasi (LD) (Oomen et al. 2013 ). Dalam tugas ini, hewan membedakan antara lokasi yang diberi hadiah dan yang tidak diberi hadiah sebagaimana ditunjukkan oleh isyarat visual CS+ dan CS− (Gambar 1A ), di mana jarak pemisahannya kecil (yaitu, lokasi yang serupa) atau besar (yaitu, lokasi yang tidak serupa). Dalam setiap sesi, kontingensi hadiah diubah setelah 9 dari 10 pilihan berurutan yang benar (“kriteria pembalikan”; Gambar 1B,C ) untuk menghindari bias spasial untuk lokasi yang diberi isyarat dan untuk memungkinkan kami menguji kemampuan diskriminasi spasial. Hewan disuntik dengan garam (perawatan kendaraan, VEH) atau CNO (perawatan uji) dan diuji pada setiap kondisi pemisahan dengan cara yang seimbang.
Bahasa Indonesia: Setelah pemeriksaan histologis, pertama-tama kami menyertakan 11 dari 20 hewan untuk analisis perilaku, berdasarkan pada apakah kami mengamati ekspresi DREADD-mCherry bilateral di DG kiri dan kanan (Gambar 1E–G ). Kami mengidentifikasi transduksi DREADD+ di dDG berdasarkan ekspresi mCherry di hilus, lapisan sel granular, dan jalur serat berlumut di sepanjang sumbu anterior-posterior. Untuk setiap subwilayah DG, kami menilai secara kualitatif apakah ada ekspresi mCherry di hemisfer kiri dan kanan (Goossens et al. 2021 ; Shen et al. 2021 ). Hewan disertakan untuk analisis lebih lanjut jika mereka menunjukkan ekspresi virus di setidaknya dua subwilayah di DG kiri dan kanan. Hal ini mengakibatkan pengecualian enam hewan dengan ekspresi virus unilateral di dDG dan tiga hewan tanpa ekspresi virus di dDG kiri maupun kanan. Hewan yang disertakan berdasarkan kriteria ini menunjukkan pola ekspresi virus (Gambar S1 ) yang sangat mirip dengan penelitian yang menargetkan DG dengan hM4Di-mCherry (Panoz-Brown et al. 2018 ; Shen et al. 2021 ) dan hM3Dq (Keenan et al. 2017 ), dengan pelabelan dominan pada lapisan sel granula, hilus, dan proyeksi serat berlumut yang berakhir di CA3. Secara khusus, mCherry diekspresikan dengan jelas dalam badan sel di lapisan sel granula dan subwilayah hilus, sementara proyeksi akson padat diamati dari DG ke CA3 (Gambar 1G dan S1A,B ; Panoz-Brown et al. 2018 ; Shen et al. 2021 ). Ekspresi mCherry diamati di bagian dorsal DG, memanjang dari -1,72 mm hingga -4,56 mm AP dari Bregma (Gambar S1 dan S2 ). Untuk menentukan apakah injeksi virus individu berhasil, kami memeriksa ekspresi mCherry di dekat lokasi injeksi anterior (-2,77 mm AP, ±1,2 mm ML, -3,77 mm DV) dan posterior (-3,7 mm AP, ±2,0 mm ML, -3,1 mm DV; lihat Bagian 2.2.2 ). Kami mengamati ekspresi di kedua belahan otak dan di kedua lokasi injeksi pada semua tikus (kira-kira antara 1,72 dan -4,56 AP; Gambar S2A–J ), kecuali tikus 11. Tikus 11 tidak menunjukkan ekspresi yang jelas di lokasi injeksi kanan posterior (Gambar S2K ), yang menunjukkan bahwa injeksi virus di lokasi ini kemungkinan gagal. Dengan demikian, berdasarkan penyebaran ekspresi virus yang terbatas pada DG dorsal, kami menganggap tidak mungkin DG posterior (meluas melebihi −4,56 mm AP dari Bregma) menjadi sasaran.
Bahasa Indonesia: Selain DG, kami mengamati pewarnaan padat terlokalisasi di CA3 yang dicirikan oleh struktur bergaris tanpa badan sel, kemungkinan menunjukkan proyeksi serat berlumut dari DG yang berakhir di CA3 (Panoz-Brown et al. 2018 ; Shen et al. 2021 ). Kami juga mengamati ekspresi mCherry dalam badan sel individu pada tingkat yang lebih rendah (Gambar S1 ), meskipun ini sulit untuk dinilai karena penyebaran struktur bergaris yang padat. Pewarnaan terlokalisasi di CA3 di kedua belahan otak diamati di setiap tikus, yaitu, tikus dengan ekspresi DREADD+ di dDG selalu mengekspresikan mCherry bersamaan di CA3, yang sangat mirip dengan pola ekspresi virus dari penelitian sebelumnya yang menargetkan DG (Shen et al. 2021 ). Kami juga mengamati ekspresi mCherry pada lapisan CA1 secara bilateral pada 3 dari 11 tikus (27%, Gambar S1A ) dan secara unilateral pada 4 dari 11 tikus (36%, Gambar S1B ), kemungkinan karena lapisan CA1 harus ditembus agar suntikan mencapai DG. Ekspresi mCherry juga diamati secara bilateral dan unilateral pada lapisan subiculum pada 3 dari 11 (27%) dan 5 dari 11 tikus (45%). Kami mengamati perilaku tugas yang secara kualitatif serupa pada tikus yang mengekspresikan DREADD secara bersamaan di CA3, CA1, dan subiculum secara bilateral (data tidak ditampilkan) dan oleh karena itu menyertakan tikus-tikus ini untuk analisis lebih lanjut. Bersama-sama, DREADD-mCherry terutama diekspresikan di bagian dorsal DG, tetapi keterlibatan bersama area CA3, CA1, dan subiculum tidak dapat dikesampingkan (lihat Bagian 4.1 ).
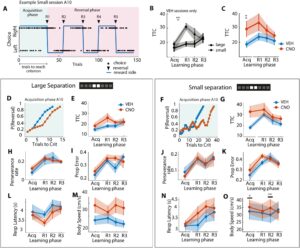
3.1 Manipulasi DREADD Sementara pada Sel DG Dorsal Mengganggu Diskriminasi Spasial Selama Akuisisi Tugas
Selanjutnya kami menentukan bagaimana pembelajaran disambiguasi spasial dipengaruhi oleh modulasi DREADD inhibitorik dari dDG dalam subset hewan dengan ekspresi DREADD+ bilateral ( N = 11). Kinerja tugas diperiksa sebagai jumlah percobaan yang diperlukan untuk mencapai kriteria pembalikan (percobaan untuk kriteria, TTC; Clelland et al. 2009 ; McTighe et al. 2009 ; Oomen et al. 2013 ). Yang penting, untuk melacak keterlibatan temporal dDG selama pembelajaran diskriminasi dalam satu sesi, kami secara terpisah memeriksa kinerja tugas untuk fase akuisisi dan fase pembalikan berikutnya (Gambar 2A ) untuk setiap kondisi perlakuan dan pemisahan. Rata-rata, hewan membuat 6 pembalikan (± 0,10 SEM) untuk sesi Besar dan 5 pembalikan (± 0,21 SEM) untuk sesi Kecil (Gambar S3A ). Terdapat efek utama pemisahan pada jumlah pembalikan yang dilakukan oleh tikus DREADD+ ( F (40) = 39,61, p = 1,82E-07, GLMM), yang menunjukkan bahwa hewan melakukan lebih sedikit pembalikan ketika diskriminasi lebih sulit. Tidak ada efek pengobatan yang diamati pada jumlah pembalikan ( F (40) = 1,10, p = 0,30, GLMM), yang menunjukkan bahwa hewan tetap mampu melakukan aturan tugas pembalikan meskipun terjadi manipulasi kemogenetik.
Untuk menentukan apakah kinerja tugas bergantung pada jarak pemisahan, pertama-tama kami membandingkan TTC antara sesi Kecil dan Besar untuk setiap fase tugas hanya untuk sesi kendaraan (lihat Tabel S1 ). Ada efek utama pemisahan pada kinerja tugas setelah pembalikan pertama dilakukan ( F (19) = 11,60, p = 0,0030, GLMM; Gambar 2B ), yang menunjukkan bahwa hewan berkinerja lebih buruk dalam sesi Kecil dibandingkan dengan sesi Besar. Tidak ada efek jarak pemisahan yang diamati untuk fase akuisisi dan pembalikan berikutnya dalam sesi yang sama ( p > 0,05, GLMM; Gambar 2B ; Gambar S3A ). Temuan ini menunjukkan bahwa hewan berkinerja lebih buruk setelah pembalikan pertama tetapi dengan cepat meningkatkan kinerja mereka dan mencapai tingkat kinerja yang sama dalam sesi yang sama terlepas dari kesulitan diskriminasi.
Selanjutnya kami menentukan bagaimana kinerja tugas dimodulasi oleh perawatan tergantung pada jarak pemisahan, di mana TTC dibandingkan antara sesi perawatan untuk setiap tingkat pemisahan dan fase tugas secara terpisah (Gambar 2A ; lihat Tabel S1 ). Untuk fase akuisisi, ada efek utama pemisahan ( F (40) = 5,49, p = 0,024, GLMM; Gambar S3C ) dan perawatan pada TTC ( F (40) = 5,75, p = 0,021; Gambar 2C ; Gambar S3D ), tetapi tidak ada efek interaksi dari faktor-faktor ini ( F (40) = 2,91, p = 0,096; Tabel S1 ). Meskipun kami mengamati tren bahwa hewan berkinerja lebih buruk ketika CNO diberikan untuk lokasi stimulus yang sama (Gambar 2F,G dan S3F ), kami tidak melakukan uji post hoc untuk mendukung pengamatan ini karena tidak adanya efek interaksi. Dengan demikian, gangguan tugas yang bergantung pada perawatan selama fase akuisisi tidak bergantung pada kesulitan tugas. Sebaliknya, kami tidak mengamati efek pengobatan pada TTC untuk pembalikan apa pun ( p > 0,05, GLMM; Gambar 2C dan S3C ). Meskipun ada efek utama pemisahan setelah hewan melakukan pembalikan pertamanya ( F (38) = 11,89, p = 0,014; Gambar S3C ), tidak ada efek interaksi selama pembalikan apa pun dan tidak ada uji post hoc yang dilakukan sebagai hasilnya ( p > 0,05, GLMM; Gambar 2D–G dan S3E,F ). Secara keseluruhan, temuan kami menunjukkan defisit diskriminasi yang bergantung pada DG selama fase perolehan awal yang pulih ke tingkat kinerja dasar dalam sesi yang sama.
Untuk menguraikan variabilitas yang diamati dalam kinerja tugas antara hewan setelah pengobatan CNO (Gambar 2C ), kami memvisualisasikan TTC secara terpisah untuk setiap tikus di seluruh fase pembelajaran (Gambar S4A–K ). Selama fase akuisisi, kami mengamati bahwa kinerja tugas terganggu setelah pengobatan CNO pada 6 tikus (Gambar S4B,C , S4F , S4H , S4J,K ). Tikus yang tersisa menunjukkan tidak ada efek pengobatan (4 tikus, Gambar S4A,D,E dan S4G ) atau kinerja tugas yang sedikit membaik (1 tikus, Gambar S4I ). Selain itu, kami menentukan bagaimana perilaku tugas dipengaruhi oleh variabilitas dalam ekspresi virus. Mayoritas tikus menunjukkan kinerja tugas yang terganggu di bawah pengobatan CNO di beberapa pembalikan ( N = 9; Gambar S3A–D , S3F,G , S3I–K ), sejalan dengan efek pengobatan pada tingkat kelompok yang kami laporkan (Gambar 2C ). Yang penting, tikus 11 (tidak menampilkan ekspresi yang jelas di lokasi injeksi posterior di belahan kanan) juga menunjukkan efek CNO yang kuat selama fase akuisisi. Meskipun sulit untuk berspekulasi berdasarkan satu hewan, kami menyimpulkan bahwa ekspresi DREADD di bagian posterior DG tidak menjelaskan efek CNO pada pembelajaran akuisisi. Selain itu, untuk menentukan apakah ada efek perancu dari jumlah hari pengujian pada kinerja tugas, kami memasangkan GLMM ke TTC dengan faktor model pengobatan, pemisahan, dan jumlah hari pengujian, seperti yang dijelaskan dalam Metode (Bagian 2.4.1 ). Kami kemudian melakukan ANOVA pada koefisien model untuk menguji efek utama dan interaksi dari pengobatan, pemisahan, dan jumlah hari pengujian. Bahasa Indonesia: Ketika mempertimbangkan fase perolehan dan pembalikan berikutnya, kami mengamati efek utama dari perlakuan ( F (36) = 4,31, p = 0,039) dan jumlah hari pengujian ( F (36) = 7,69, p = 0,006), tetapi tidak mengamati efek interaksi apa pun ( p > 0,05). Kami juga melakukan analisis yang sama hanya pada fase perolehan; namun, penyertaan hari pengujian sebagai faktor tetap menurunkan daya analisis kami dan tidak ada efek utama maupun interaksi yang ternyata signifikan. Untuk memperhitungkan daya yang berkurang, dan mempertimbangkan hasil yang konsisten dan tidak signifikan untuk faktor interaksi apa pun, kami mengulangi analisis dengan hanya menyertakan efek utama dan, konsisten dengan hasil sebelumnya, kami mengamati efek utama untuk perlakuan ( F (39) = 4,47, p = 0,043) dan pemisahan ( F (39) = 7,64, p = 0,010), tetapi hanya tren yang hampir signifikan untuk hari pengujian ( F (39) = 3,965, p = 0,056). Secara khusus, kami mengamati bahwa kinerja tugas dalam fase akuisisi sedikit membaik di seluruh hari pengujian (Gambar S3G ). Namun demikian, tidak adanya efek interaksi menunjukkan bahwa gangguan tugas yang bergantung pada CNO tidak bergantung pada jumlah hari pengujian.
Untuk menentukan apakah ukuran lain dari kinerja tugas dipengaruhi oleh modulasi dDG, kami juga membandingkan proporsi pilihan yang salah (proporsi kesalahan, kebalikan dari proporsi yang benar; Gilbert et al. 2001 ; Lee dan Solivan 2010 ; Oomen et al. 2013 , 2015 ), waktu yang dibutuhkan untuk melaporkan pilihan (latensi respons; Oomen et al. 2013 ), kecenderungan hewan untuk bertahan pada pilihan sebelumnya (tingkat ketekunan) dan akurasi spasial dari pilihan yang dilaporkan (lihat Tabel S1 ). Tidak ada efek perlakuan pada ukuran kinerja ini untuk setiap tingkat pemisahan dan fase tugas secara terpisah ( p > 0,05, uji GLMM dan Wald; Gambar 2H–L , Gambar 2N ; Gambar S5 ). Dengan demikian, tidak ada efek manipulasi dDG pada kemampuan hewan untuk melaporkan pilihannya selama tugas. Akhirnya, untuk menyelidiki akurasi spasial pilihan, kami mengukur distribusi respons untuk lokasi target (isyarat) dan non-target (nonisyarat, yaitu kosong). Distribusi spasial tusukan hidung tidak mengungkapkan perbedaan antara kondisi perlakuan terlepas dari jarak pemisahan dan fase tugas (lihat Tabel S1 ; p > 0,05, uji Kolmogorov Smirnov; Gambar S6A,B ). Temuan ini menunjukkan bahwa inaktivasi dDG tidak mengganggu kemampuan hewan untuk menemukan lokasi stimulus isyarat di ruang angkasa. Bersama-sama, temuan kami menunjukkan bahwa CNO tidak memengaruhi kemampuan hewan untuk melaporkan pilihannya selama tugas diskriminasi, atau kemampuan untuk secara spasial menemukan lokasi target isyarat, kecuali untuk efek CNO pada kemampuan untuk merespons secara berurutan dan benar pada sisi yang diberi hadiah (Gambar 2C dan S4C ).
Selanjutnya kami meneliti kemungkinan bahwa defisit diskriminasi yang diamati (Gambar 2C ) dapat disebabkan oleh efek samping CNO yang dimetabolisme menjadi clozapine pada perilaku lokomosi (Gomez et al. 2017 ; MacLaren et al. 2016 ). Kami mengukur kecepatan gerakan pada sebagian hewan selama keterlibatan tugas dan yang dapat kami peroleh pelacakan gerakan yang andal di seluruh sesi perekaman ( N = 7; Gambar S6C,E ; lihat Tabel S1 ). Ada efek interaksi antara pemisahan dan perlakuan pada kecepatan tubuh selama fase akuisisi ( F (28) = 5,49, p = 0,027, GLMM), di mana hewan bergerak secara signifikan lebih cepat untuk CNO dibandingkan dengan perlakuan VEH selama fase akuisisi ( W = 2,58, p = 0,031, uji Wald) dan setelah pembalikan kedua sesi Kecil ( W = 3,27, p = 0,0063, uji Wald; Gambar 2O ; Gambar S6F ). Menariknya, efek fase tugas dan ketergantungan pengobatan pada kecepatan tubuh ini diamati secara selektif ketika hewan membuat pilihan yang benar (Gambar S6I ) dan ke kiri (Gambar S6M ). Sebaliknya, tidak ada efek CNO pada kecepatan tubuh yang diamati selama sesi Besar (Gambar 2L ; Gambar S6D ), terlepas dari kebenaran uji coba (Gambar S6G,H ) dan apakah respons dibuat ke sisi kiri atau kanan (Gambar S6K,L ). Dengan demikian, efek CNO pada kecepatan tubuh tidak digeneralisasi di seluruh tingkat pemisahan, yang menunjukkan bahwa tidak ada efek umum pemberian CNO pada aktivitas penggerak.
3.2 Peningkatan Pergantian Pilihan Mendasari Gangguan Pembelajaran Diskriminasi Selama Modulasi DG
Defisit diskriminasi dependen dDG yang diamati selama fase akuisisi (Gambar 2C ) dicirikan oleh peningkatan jumlah uji coba yang diperlukan untuk mencapai kriteria kinerja. Dengan kata lain, hewan menunjukkan kemampuan awal yang terganggu untuk membuat pilihan yang benar secara berurutan, yang menunjukkan pembelajaran akuisisi yang lebih lambat di seluruh uji coba. Interpretasi alternatif bisa jadi bahwa hewan lebih sering berganti-ganti antara pilihan sebagai strategi untuk memaksimalkan keluaran hadiah ketika diskriminasi spasial bersifat ambigu. Misalnya, hewan mungkin kesulitan mengidentifikasi sisi yang diberi hadiah ketika asosiasi tempat-hasil belum terbentuk, yaitu selama fase pembelajaran akuisisi. Untuk membedakan antara kedua interpretasi ini, kami berupaya menangkap dinamika pembelajaran tempat-hasil dan volatilitas perilaku pilihan di seluruh uji coba dengan dua varian model pembelajaran penguatan (RL) yang sesuai dengan tugas perilaku yang ada (Rescorla dan Wagner 1972 ; Sutton dan Barto 2018 ; Metha et al. 2020 ). Model RL pertama yang kami gunakan (selanjutnya: “Model RL Sederhana”) mengkarakterisasi dinamika pembelajaran dengan dua parameter. Pertama, tingkat pembelajaran ( alpha ) menunjukkan seberapa cepat hewan menyesuaikan pilihan mereka di seluruh percobaan dan mencerminkan kekuatan asosiasi antara lokasi dan hadiah. Kedua, sensitivitas hadiah ( beta ) menunjukkan seberapa sensitif hewan terhadap perbedaan nilai hadiah. Model RL kedua (selanjutnya: “Perseverance RL – PRL – model”; Metha et al. 2020 ) menyertakan parameter tambahan selain tingkat pembelajaran dan sensitivitas hadiah: tingkat ketekunan ( delta ), yang menunjukkan kecenderungan hewan untuk bertahan atau berganti-ganti dalam perilaku pilihan mereka.
Kami memasang model RL untuk setiap hewan, kondisi tugas, dan fase pembelajaran secara percobaan per percobaan (Gambar 3A dan S7A ), yang memungkinkan kami memperoleh estimasi parameter secara terpisah untuk setiap tikus per kondisi tugas dan fase pembelajaran. Model PRL mengembalikan nilai Akaike Information Criterion (AIC) yang lebih rendah dibandingkan dengan model RL sederhana untuk setiap model yang sesuai untuk setiap hewan ( N = 11, Gambar 3B dan S7B ). Mengingat bahwa nilai AIC yang lebih rendah menunjukkan kecocokan model yang jauh lebih baik, temuan ini menunjukkan bahwa variabilitas dalam perilaku pilihan lebih baik ditangkap jika kita memperhitungkan kecenderungan hewan untuk bertahan dalam pilihan mereka. Selain itu, estimasi percobaan per percobaan dari prediksi model PRL berkorelasi secara signifikan lebih kuat dengan perilaku pilihan hewan yang diamati dibandingkan dengan model RL sederhana (Gambar 3C dan S7C ). Dengan demikian, temuan kami menunjukkan bahwa model Perseverance RL lebih cocok untuk perilaku pilihan dibandingkan dengan model RL Sederhana.
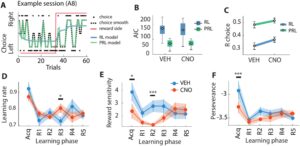
Selanjutnya kami membandingkan nilai parameter yang paling sesuai di seluruh kondisi untuk model PRL (lihat Tabel S1 ). Dalam model PRL, kami tidak mengamati efek utama dari perlakuan (Gambar 3D ) atau pemisahan (Gambar S7D ) pada parameter laju pembelajaran ( alpha ) untuk setiap fase tugas ( p > 0,05, GLMM; Tabel S1 ), dengan pengecualian bahwa laju pembelajaran lebih tinggi untuk CNO dibandingkan dengan sesi kendaraan setelah pembalikan ketiga dilakukan ( F (35) = 7,13, p = 0,011; Gambar 3D ). Sebagai perbandingan, parameter sensitivitas penghargaan ( beta ) berkurang secara signifikan setelah perlakuan CNO selama fase perolehan ( F (40) = 4,34, p = 0,044) dan setelah pembalikan kedua dilakukan ( F (36) = 16,18, p = 2,80E-4; Gambar 3E ). Tidak ada efek pemisahan pada sensitivitas hadiah untuk setiap fase tugas ( p > 0,05, GLMM; Gambar S7E ). Akhirnya, parameter ketekunan ( delta ) secara signifikan lebih rendah setelah CNO dibandingkan dengan perlakuan kendaraan selama fase perolehan ( F (40) = 64,54, p = 7,11E-10; Gambar 3F ). Nilai ketekunan yang lebih rendah menunjukkan kecenderungan yang lebih tinggi untuk berganti-ganti antara pilihan setelah perlakuan CNO. Kami tidak menemukan efek pemisahan pada ketekunan pada setiap fase tugas ( p > 0,05, GLMM; Gambar S7F ). Bersama-sama, model PRL mengungkapkan bahwa sensitivitas hadiah yang berkurang dan pergantian pilihan yang ditingkatkan secara temporal dikaitkan dengan defisit diskriminasi spasial yang bergantung pada dDG selama fase perolehan, tanpa hubungan dengan jarak pemisahan.
4 Diskusi
Tujuan utama dari penelitian ini adalah untuk menyelidiki peran akut dan kausal dari DG dorsal (dDG) dalam menghilangkan ambiguitas stimulus spasial yang serupa. Kami menemukan bahwa disfungsi dDG sementara yang dimediasi DREADDs selama tugas diskriminasi lokasi menyebabkan defisit diskriminasi sementara selama perolehan tugas (Gambar 2C ). Defisit diskriminasi ini tidak bergantung pada jarak pemisahan, yang menunjukkan bahwa efek yang kami amati berlaku untuk diskriminasi lokasi spasial yang serupa dan tidak serupa. Dengan demikian, penelitian kami menunjukkan peran dDG dalam pembelajaran asosiasi tempat-hadiah ketika hewan melakukan tugas diskriminasi lokasi, seperti yang ditunjukkan oleh dua temuan baru. Pertama, kinerja tugas cepat pulih ke tingkat dasar setelah fase perolehan (Gambar 2C ), yang menunjukkan bahwa dDG secara selektif terlibat selama pembentukan awal asosiasi tempat-hadiah. Kedua, studi pemodelan kami mengungkapkan bahwa defisit yang bergantung pada dDG ini dikaitkan dengan penurunan sensitivitas hadiah (Gambar 3E ) dan peningkatan kecenderungan untuk berganti-ganti antara pilihan di seluruh percobaan (Gambar 3F ). Secara keseluruhan, studi kami memberikan bukti baru yang menunjukkan bahwa, ketika kemogenetika—ketimbang lesi permanen—digunakan, dDG terlibat secara akut namun sementara dalam pembelajaran perolehan asosiasi tempat-hasil.
4.1 Modulasi Bilateral Transien pada DG Dorsal Menyebabkan Defisit Diskriminasi Spasial—Kemogenetika Dibandingkan Lesi Permanen
Temuan kami bahwa diskriminasi stimulus spasial yang serupa, sebagai lawan dari yang tidak serupa, tidak bergantung pada dDG didasarkan pada efek interaksi yang tidak ada antara pemisahan dan pengobatan pada TTC (Tabel S1 ). Namun, variabilitas yang diamati dalam ekspresi virus (Gambar S2 ) dan kinerja tugas (Gambar S4 ) antara hewan kemungkinan menurunkan kekuatan model statistik kami. Pada gilirannya, ini dapat menjelaskan perbedaan antara studi kami dan studi lesi sebelumnya yang menunjukkan efek tergantung pemisahan pada disfungsi dDG (Gilbert et al. 2001 ; Hunsaker dan Kesner 2008 ; Morris et al. 2012 ; Lee dan Solivan 2010 ). Untuk mendukung hal ini, kami mengamati tren yang tidak signifikan terhadap interaksi antara pengobatan dan jarak pemisahan pada TTC (Tabel S1 ), yang mengarah pada kemungkinan peran dDG dalam membedakan stimulus spasial yang serupa.
Meskipun demikian, studi kami menantang pandangan yang dianut secara luas tentang dDG dalam disambiguasi spasial berbutir halus seperti yang disarankan oleh lesi sebelumnya (Gilbert et al. 2001 ; Hunsaker dan Kesner 2008 ; Morris et al. 2012 ; Lee dan Solivan 2010 ) dan studi gene knock-out (McHugh et al. 2007 ; Kannangara et al. 2015 ; Yun et al. 2023 ; tetapi lihat Oomen et al. 2015 ) pada hewan pengerat. Penjelasan yang mungkin untuk perbedaan ini adalah bahwa DG lebih sensitif terhadap disfungsi setelah lesi dibandingkan dengan kemogenetika. Memang, racun seperti kolkisin dan asam ibotenat telah terbukti menimbulkan kerusakan permanen dan hilangnya fungsi dalam subwilayah ini (Gilbert et al. 2001 ; Lee dan Kesner 2003 ; Lee dan Kesner 2004 ; Jerman et al. 2005 ). Penelitian sebelumnya telah menunjukkan bahwa kerusakan jaringan permanen memengaruhi area hilir dalam sirkuit saraf dengan cara seperti kaskade (Otchy et al. 2015 ; Vaidya et al. 2019 ) atau menyebabkan kompensasi fungsi yang terpengaruh melalui area lain dalam sirkuit fungsional (Zelikowsky et al. 2013 ; Hong et al. 2018 ; diulas dalam Vaidya et al. 2019 ). Dalam kasus seperti itu, disfungsi dalam sirkuit saraf yang mendukung pembelajaran diskriminasi mungkin lebih parah karena tidak hanya menyangkut DG, tetapi juga area hilirnya seperti CA3 dan CA1. Memang, lesi sel granular di DG dengan kolkisin pada tikus yang membedakan antara pemandangan visual telah terbukti tidak hanya mengganggu kinerja perilaku, tetapi juga menurunkan kemampuan sel CA3 hilir untuk membedakan antara pemandangan yang ambigu dengan modulasi laju penembakan yang bergantung pada pemandangan (Lee dan Lee 2020 ). Sebagai perbandingan, penelitian kami menggunakan DREADD reversibel untuk memodulasi aktivitas penembakan sel eksitatori di DG secara sementara, sehingga lebih masuk akal bahwa sirkuit fungsional dipertahankan meskipun ada manipulasi kemogenetik, yang mengakibatkan defisit terkait diskriminasi yang lebih halus.
Penjelasan alternatif, namun saling melengkapi dapat dikaitkan dengan pengamatan kami bahwa kepadatan ekspresi DREADD-mCherry+ di area target dDG bervariasi antara hewan setelah verifikasi histologis (Gambar S1 ). Sejalan dengan ini, kami mengamati variabilitas besar dalam kinerja tugas di antara tikus individu yang diobati dengan CNO dibandingkan dengan pengobatan salin (Gambar 2C ). Selain itu, kami mengamati ko-ekspresi DREADD-mCherry+ di CA3, CA1, dan subiculum dalam sebagian besar hewan kami (lihat Hasil, Gambar S1A ). Ini mungkin telah memengaruhi kinerja perilaku secara berbeda, sehingga sulit untuk memperkirakan sejauh mana ko-ekspresi di subwilayah ini memengaruhi kinerja tugas dalam penelitian kami. Satu penelitian sebelumnya menunjukkan bahwa lesi CA3 dan CA1 tidak mengganggu kemampuan untuk membedakan antara lokasi yang berdekatan pada tikus (Gilbert et al. 2001 ), yang membantah kemungkinan bahwa ko-penargetan subwilayah ini memengaruhi kinerja tugas dalam penelitian kami. Bertentangan dengan ini, sejumlah besar studi telah mengusulkan bahwa sirkuit saraf yang mendukung pembelajaran disambiguasi tidak hanya melibatkan DG, tetapi juga CA3 (GoodSmith et al. 2019 ; Lee et al. 2015 ; Lee dan Lee 2020 ; Leutgeb et al. 2007 ; diulas dalam Rolls 2013 ) yang menjadi tempat DG memproyeksikan secara rapat melalui serat berlumut (diulas dalam Amaral dan Witter 1989 ). Mengingat bahwa CA1 dan subiculum biasanya tidak terlibat dalam pembelajaran disambiguasi, kami berspekulasi bahwa co-ekspresi dalam CA3 mungkin telah mengacaukan sebagian efek perlakuan yang bergantung pada DG pada diskriminasi spasial yang diamati dalam studi kami.
Selain dari efek off-target dan kompensasi yang memengaruhi kinerja tugas, penelitian sebelumnya juga menunjukkan bahwa lesi DG menyebabkan hiperaktivitas (Barone Jr et al. 1992 ; Emerich dan Walsh 1990 ). Untuk memeriksa apakah ada efek perancu dari gerakan motorik setelah penargetan kemogenetik DG, kami mengukur kecepatan tubuh selama keterlibatan tugas. Hewan cenderung bergerak lebih cepat, tetapi hanya selama fase akuisisi dan setelah pembalikan kedua sesi Kecil di bawah CNO (Gambar 2N dan S6F ), dan khususnya dalam uji yang benar (Gambar S6I ) dan ke kiri (Gambar S6M ). Temuan ini menunjukkan bahwa tidak ada efek umum kemogenetik pada penggerak selama tugas. Dengan demikian, kami berasumsi bahwa hiperaktivitas yang diamati selama pembelajaran akuisisi (Gambar 2O ) merupakan korelasi dari gangguan perilaku yang dialami oleh hewan setelah disfungsi sementara DG (Gambar 2C ).
4.2 Pembelajaran Diskriminasi Spasial: Memori Kerja, Pembelajaran Tempat-Hasil, atau Pembelajaran Spasial
Bahasa Indonesia: Untuk memahami aspek pembelajaran spasial mana yang terpengaruh oleh disfungsi dDG, kami menilai pembelajaran diskriminasi secara terpisah selama fase perolehan dan fase pembalikan berikutnya (Gambar 1C ), serta dinamika pembelajaran yang mendasari pembelajaran tempat-hasil menggunakan model pembelajaran penguatan (O’Reilly dan den Ouden 2015 ; Metha et al. 2020 ). Keterlibatan kausal sementara dari dDG hanya selama fase perolehan (Gambar 2C ) membuat tidak mungkin bahwa defisit diskriminasi dapat dijelaskan sebagai memori kerja umum atau gangguan persepsi, karena defisit seperti itu akan terus berlanjut di seluruh pembalikan. Kami tidak mengamati bias respons untuk lokasi isyarat yang dipisahkan kiri atau kanan (Gambar S5G,H ), yang menunjukkan bahwa pembelajaran respons spasial berdasarkan kerangka acuan egosentris juga utuh pada hewan-hewan ini (misalnya, lokasi hadiah berada di sisi kiri hewan dan bukan di kanannya). Hal ini sesuai dengan temuan sebelumnya bahwa jenis pembelajaran respons ini tidak bergantung pada hipokampus dan bergantung pada striatum dorsal (Packard dan McGaugh 1996 ; Featherstone dan McDonald 2004 ).
Sebaliknya, keterlibatan selektif dan kausal dari dDG hanya menyangkut pembelajaran awal tentang asosiasi tempat-hadiah (Gambar 2C ), yang menunjuk pada defisit dalam pembelajaran untuk membedakan lokasi yang diberi hadiah versus yang tidak diberi hadiah (McDonald dan White 1995 ; Gilbert et al. 2001 ; Hunsaker dan Kesner 2008 ; McHugh et al. 2007 ; Morris et al. 2012 ; Lee dan Solivan 2010 ; Kannangara et al. 2015 ; Yun et al. 2023 ). Secara khusus, kemampuan yang terganggu untuk merespons secara berurutan dan benar ke lokasi target meskipun menerima hadiah mengarah pada defisit pembelajaran atau spasial: baik defisit dalam mempelajari tempat mana yang dikaitkan dengan hadiah atau, sebagai alternatif, defisit dalam memisahkan lokasi stimulus secara spasial. Kami juga tidak mengamati perbedaan dalam distribusi spasial tusukan kosong di sekitar lokasi target antara sesi perawatan (Gambar S6A,B ), yang menunjukkan bahwa hewan dengan disfungsi dDG tidak merespons secara kurang tepat secara spasial ketika CNO diberikan dibandingkan dengan sesi perawatan kontrol. Selain itu, dDG diaktifkan selama fase akuisisi terlepas dari pemisahan spasial (Gambar 2C ), yang juga menentang defisit spasial. Sebaliknya, pengamatan bahwa sensitivitas perilaku pilihan terhadap perbedaan nilai hadiah berkurang setelah inaktivasi dDG selama fase akuisisi (Gambar 3E ) mengarah pada defisit pembelajaran tempat-hadiah. Selain itu, hewan merespons kurang konsisten terhadap stimulus yang diberi hadiah di seluruh percobaan berturut-turut (Gambar 2C ) dan lebih sering bergantian (Gambar 3F ). Ini menunjukkan bahwa disfungsi dDG menyebabkan penurunan baik dalam kemampuan untuk mengaitkan hadiah ke lokasi dan dalam stabilitas perilaku pilihan. Efek yang kami amati mengarah pada peran dDG dalam mempelajari atau mempertahankan representasi tempat-hadiah yang benar selama akuisisi asosiasi tempat-hasil, yaitu, mempelajari lokasi mana yang menghasilkan hadiah. Peralihan pilihan yang mudah berubah biasanya dikaitkan dengan disfungsi pada korteks frontal (Deserno et al. 2020 ); aspek efek inaktivasi DG yang dilaporkan di sini mungkin secara tentatif terkait dengan fungsi korteks frontal dengan mempertimbangkan bahwa sirkuit hipokampus hilir DG (CA3, CA1 dan subiculum) sangat menonjol ke PFC medial.
4.3 Mekanisme Saraf yang Mendukung Kontribusi Dentate Gyrus terhadap Pembelajaran Place-Outcome
Studi kami menunjukkan peran dDG dalam pembelajaran asosiasi tempat-imbalan. Secara khusus, penargetan dDG menyebabkan kemampuan diskriminasi yang terganggu (Gambar 2C ) dan sensitivitas imbalan yang berkurang (Gambar 3E ) selama pembentukan awal atau pengodean asosiasi tempat-hasil. Namun, pertanyaannya tetap bagaimana dDG berkontribusi pada pembentukan representasi tempat-hasil.
Pertanyaan ini dapat didekati, pertama, dengan mempertimbangkan hasil dari studi DG menggunakan paradigma pembelajaran lain. Misalnya, Kheirbek et al. ( 2013 ) menemukan bahwa manipulasi optogenetik DG mengungkapkan bahwa sel-sel granula mengendalikan dorongan eksploratif dan pengodean memori ketakutan kontekstual, tetapi bukan pengambilannya. Ini konsisten dengan efek yang kami temukan pada pembelajaran awal dan pergantian dalam paradigma pembelajaran nafsu makan, serta dengan peran neurogenesis DG dalam meningkatkan representasi spasial (Frechou et al. 2024 ). Dalam nada yang sama, manipulasi optogenetik sel-sel somatostatin-positif dalam DG merusak pengodean memori spasial dan preferensi tempat yang dikondisikan tetapi, sekali lagi, bukan pengambilannya (Yen et al. 2022 ). Salah satu target manipulasi DREADD kami adalah populasi sel lumut dDG, yang baru-baru ini terbukti berkontribusi pada pengodean ruang dan disambiguasi konteks spasial (Huang et al. 2024 ). Studi terakhir berbeda dari studi kami, bagaimanapun, dalam konteks yang berbeda disajikan kepada tikus dengan kepala tetap dalam pengaturan realitas virtual. Studi kami lebih sebanding dengan studi lain yang menunjukkan DG terlibat secara akut selama diskriminasi konteks yang serupa tetapi berbeda ketika hewan mengalami hasil negatif (van Dijk dan Fenton 2018 ). Studi ini setuju dengan pengamatan kami bahwa (i) DG terlibat selama diskriminasi spasial dalam (ii) lingkungan yang secara fisik identik dengan lokasi tujuan yang direlokasi ketika (iii) hewan secara aktif memperoleh asosiasi tempat-hasil. Singkatnya, studi kami secara umum sejalan dengan studi-studi sebelumnya pada DG yang konsisten dengan peran dalam akuisisi dan pengkodean memori, baik dalam tugas-tugas di mana tempat atau konteks menjadi terkait dengan hasil positif atau negatif.
Kedua, mekanisme dan jalur potensial yang melaluinya dDG dapat terlibat dalam pembelajaran tempat-hasil harus dipertimbangkan. Karena DG memproyeksikan secara padat ke area CA3 dan, dari sana, secara tidak langsung memengaruhi area CA1 dan subiculum (diulas dalam Amaral dan Witter 1989 ), informasi tentang tempat dan konteks yang terkait dengan hasil yang berharga dapat mencapai struktur seperti striatum ventral dan PFC medial, yang sangat terlibat dalam ekspektasi penghargaan, penilaian isyarat dan tindakan, dan perilaku yang diarahkan pada tujuan (Alexander et al. 1986 ; Thierry et al. 2000 ; Voorn et al. 2004 ; Haber et al. 2006 ; Roberts et al. 2007 ). Sejalan dengan ini, Sasaki et al. ( 2018 ) menemukan aktivitas yang ditimbulkan oleh imbalan dalam sel dentate di lokasi imbalan pada tikus yang melakukan tugas memori kerja spasial, yang menunjukkan bahwa sel DG mengodekan representasi tempat-hasil. Yang penting, aktivitas yang ditimbulkan oleh imbalan dalam DG dikaitkan dengan peningkatan laju riak gelombang tajam (SWR) di CA3, di mana lesi sel granula mengurangi laju SWR di CA3. Studi ini mengimplikasikan bahwa aktivitas jaringan yang ditimbulkan oleh imbalan di CA3 dapat didorong oleh DG, di mana, pada gilirannya, kolateral berulang dari CA3 dapat memperkuat asosiasi tempat-hasil untuk mendukung pembelajaran tempat-hadiah di area hilir. Sejalan dengan ini, proyeksi CA1/subicular ke striatum ventral telah terlibat dalam pembelajaran tempat-hadiah (sering disebut preferensi tempat terkondisi; Ito et al. 2008 ; Lansink et al. 2009 ; Trouche et al. 2019 ). Pada level area hilir CA1, studi sebelumnya telah menunjukkan bahwa tempat yang terkait dengan reward dikodekan oleh sel tempat (Hollup et al. 2001 ; Hölscher et al. 2003 ; Lansink et al. 2012 ; Gauthier and Tank 2018 ; diulas dalam Sosa and Giocomo 2021 ). Misalnya, kepadatan dan laju penembakan medan tempat sel CA1 ditingkatkan di dekat lokasi tujuan yang terkait dengan reward (Hollup et al. 2001 ; Hölscher et al. 2003 ; Gauthier and Tank 2018 ). Selain itu, medan tempat di CA1 berkurang ukurannya di lokasi reward dalam Y-maze, terutama saat lampu isyarat prediksi reward dinyalakan (Lansink et al. 2012 ), yang menunjukkan pengkodean tempat menjadi lebih halus saat dikaitkan dengan hasil positif.
Sejauh mana dDG mengodekan informasi spasial murni atau juga mengirimkan sinyal terkait imbalan ke area hilir ini masih harus diselidiki lebih rinci. Studi terbaru menunjukkan bahwa sel dentata tidak hanya mengodekan informasi spasial tetapi juga informasi nonspasial, termasuk informasi terkait imbalan (van Dijk dan Fenton 2018 ; Sasaki et al. 2018 ), objek (GoodSmith et al. 2022 ) dan isyarat sensorik (Tuncdemir et al. 2022 , Tuncdemir et al. 2023 ). Misalnya, GoodSmith et al. ( 2022 ) menemukan bahwa sel granula dan sel berlumut mengodekan peta spasial lingkungan yang stabil tetapi juga memetakan ulang sebagai respons terhadap perubahan terkait objek di lingkungan. Ini menyiratkan bahwa kedua subpopulasi DG mampu mengodekan informasi spasial dan nonspasial. Dalam studi terkini, histologi mengungkap sel-sel padat yang mengekspresikan DREADD+ di lapisan sel granula dan regio hilar (Gambar 1F,G dan S1A ), yang terakhir sebagian besar berisi sel-sel berlumut (Senzai dan Buzsáki 2017 ; GoodSmith et al. 2017 ). Sel-sel berlumut hilar telah terbukti menggerakkan interneuron DG lokal dengan kuat (Jinde et al. 2012 ; Scharfman et al. 1990 ), sehingga memengaruhi sel-sel granula yang memproyeksikan ke CA3 (diulas dalam Amaral dan Witter 1989 ), yang pada gilirannya dianggap penting untuk pembelajaran asosiatif tempat-tempat dengan objek dan rangsangan sensorik (Morris et al. 2012 ). Efek perilaku yang kami amati dalam penelitian saat ini karena itu dapat muncul karena terganggunya fasilitasi yang digerakkan oleh DG dari pengikatan peristiwa yang menonjol secara motivasi ke tempat-tempat yang tepat oleh area hilir seperti CA3, CA1-subiculum (Lee dan Jung 2017 ) dan karenanya ke striatum ventral dan PFC medial. Koneksi hipokampus-prefrontal-striatal ini telah dihipotesiskan untuk memungkinkan korteks prefrontal memperbarui status tugas perilaku dan mendukung pengambilan keputusan yang fleksibel (Brown et al. 2012 , 2016 ; Brown dan Stern 2014 ; Ferbinteanu 2016 ; Rusu dan Pennartz 2020 ). Hal ini, pada gilirannya, menunjukkan bagaimana disfungsi dDG yang diamati dalam penelitian kami dapat dikaitkan dengan gangguan pengambilan keputusan. Secara khusus, keluaran spasial yang terdegradasi dari hipokampus, yang disampaikan ke striatum ventral dan korteks prefrontal, mungkin telah menyebabkan sistem hipokampus-prefrontal-ventral striatal tidak dapat belajar memilih lokasi tujuan yang benar, meskipun dikaitkan dengan penghargaan.
Mekanisme alternatif—tetapi tidak saling eksklusif—menyatakan bahwa proyeksi dari mesensefalon dan/atau batang otak ke DG berkontribusi secara langsung pada pembelajaran yang bergantung pada imbalan di tingkat DG itu sendiri (lih. Redondo et al. 2014 ). Hasil dari Han et al. ( 2020 ) menunjukkan bahwa proyeksi glutamatergik dari area tegmental ventral ke DG berkontribusi pada preferensi tempat terkondisi yang diinduksi opioid, sedangkan Petter et al. ( 2023 ) menyajikan bukti untuk peran kausal proyeksi dopaminergik dari Locus Coeruleus ke DG dalam penguatan operan (stimulasi diri). Studi masa depan harus menunjukkan mekanisme mana yang mungkin terlibat dalam jenis pembelajaran tempat-hasil dalam lingkungan yang sama seperti yang dijelaskan di sini. Terlepas dari mekanisme pastinya, kami mencatat bahwa keterlibatan kausal DG dalam pembelajaran spasial berbasis valensi menguntungkan secara fungsional, karena secara strategis diposisikan untuk memengaruhi kaskade struktur otak yang besar dan divergen yang menerima keluaran hipokampus, termasuk berbagai macam struktur lobus temporal medial dan korteks posterior.
4.4 Kesimpulan
Sebagai kesimpulan, penelitian kami memberikan bukti keterlibatan mekanistik dDG dalam mempelajari asosiasi tempat-hadiah. Penelitian selanjutnya harus mengungkap dasar-dasar peran ini di tingkat sirkuit, khususnya interaksi antara dDG dan daerah otak lainnya.